Shiny app presenting clustering results
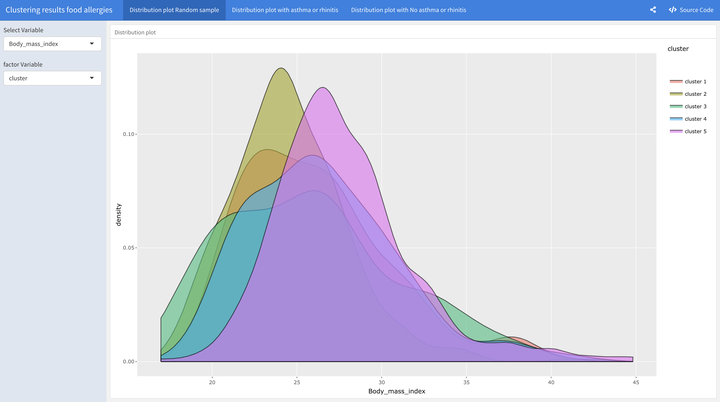
Clustering is central to many data-driven application domains and it has been investigated intensively in terms of algorithms and distance functions. Some of the most used traditional clustering methods are k-means and Hierarchical clustering. Both methods suffer from many issues when dealing with highly hetroginuoius data types. A typical challenge in clustering heterogeneous data lies in handling both numerical and categorical variables at the same time. Many commonly used approaches are limited in reflecting the correct distance that is needed to perform a good clustering. Another challenge in these classical algorithms is the definition of the distance matrix. Finding the right way to measure the distance between objects has a huge influence on the clustering performance. Both k-means and Hierarchal clustering constitute a vast majority of the unsupervised statistical methods that are used in the phenotyping within the airway disease literature. When data is large enough, new deep unsupervised and semi-supervised learning methods outperform traditional clustering methods in many ways. We plan to utilize the huge steps and findings in the area of deep unsupervised learning in our various phenotyping projects.
Rani Basna
Researcher | Data Scientist | Mathematician
My research interests include Machine learning, mathematical statistics, Mean field game theory, functional data analysis.